
What’s a Cove?
.jpg)
This is a cove. Or so I always thought. Apparently most of America calls it a cul-de-sac.
Where I grew up in the suburbs east of Memphis, these short, dead-end streets common across US suburbia are called coves. Two out of the three houses I lived in growing up there were on coves. As in the street name was actually Cove (not Street, Road, or Lane) and had the USPS designated abbreviation “Cv”. Coves are so ubiquitous in these neighborhoods that my mom created a diversion called a “Cove Spin” that simply involved driving down a cove, turning around, and driving back out. Fun times!
My current house in suburban Denver is on a cove. Recently my sister and some friends were over and she referenced the cove in conversation. Some friends did a double take and asked, “What is a cove?? Don’t you mean cul-de-sac??” Another friend, who also happened to be from Memphis, explained that coves are “a Memphis Thing”.
Is this true?
I downloaded data for all the roads in the US from the US Census Bureau (over 18 million) and used everyone’s favorite hot, new database, DuckDB, to find out.
It’s a Memphis Thing
Coves aren’t explicitly unique to the Memphis area, but Memphis and the Mid-South (western Tennessee, northern Mississippi, eastern Arkansas) indisputably make up the cove capital of the country.
Click here to open a full screen interactive map in a new tab
Of the 26,051 coves in the US, 5,706 are located in the Memphis metro area alone (Shelby County, TN and DeSoto County, MS). Thats nearly one-quarter of all US coves concentrated in a single city!
Coves are also common in the rest of the Mid-South. West Tennessee, northern Mississippi, and eastern Arkansas are home to a combined total of 11,599 coves, or 45% of all US coves.
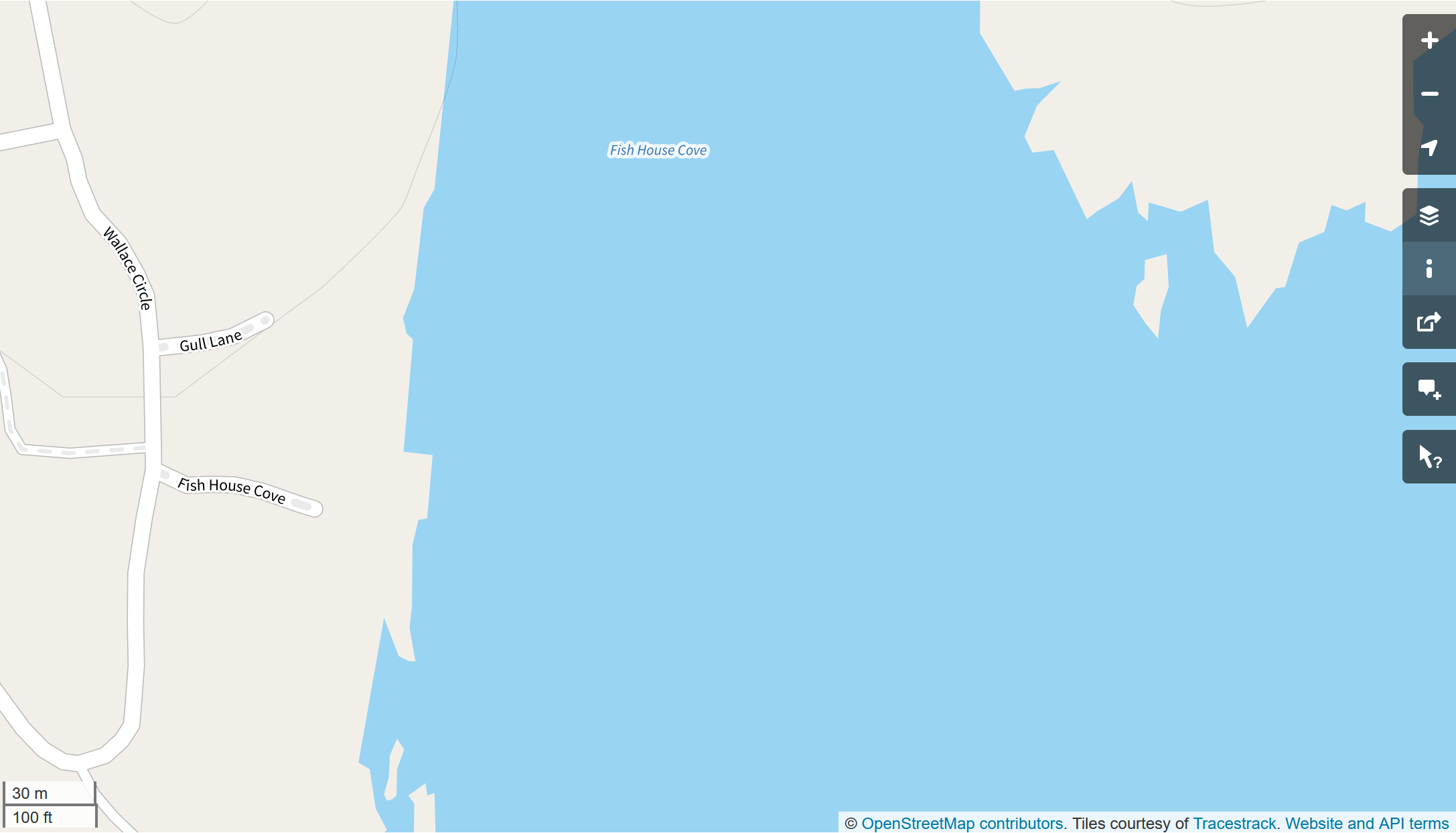
The remaining 55% of coves concentrated in a few metro areas like Austin, TX, San Antonio, TX and Salt Lake City, UT or along coasts or rivers where the names were likely inspired by the geographic features in the nearby waterways. For example, see Fish House Cove on Fish House Cove in Maine.
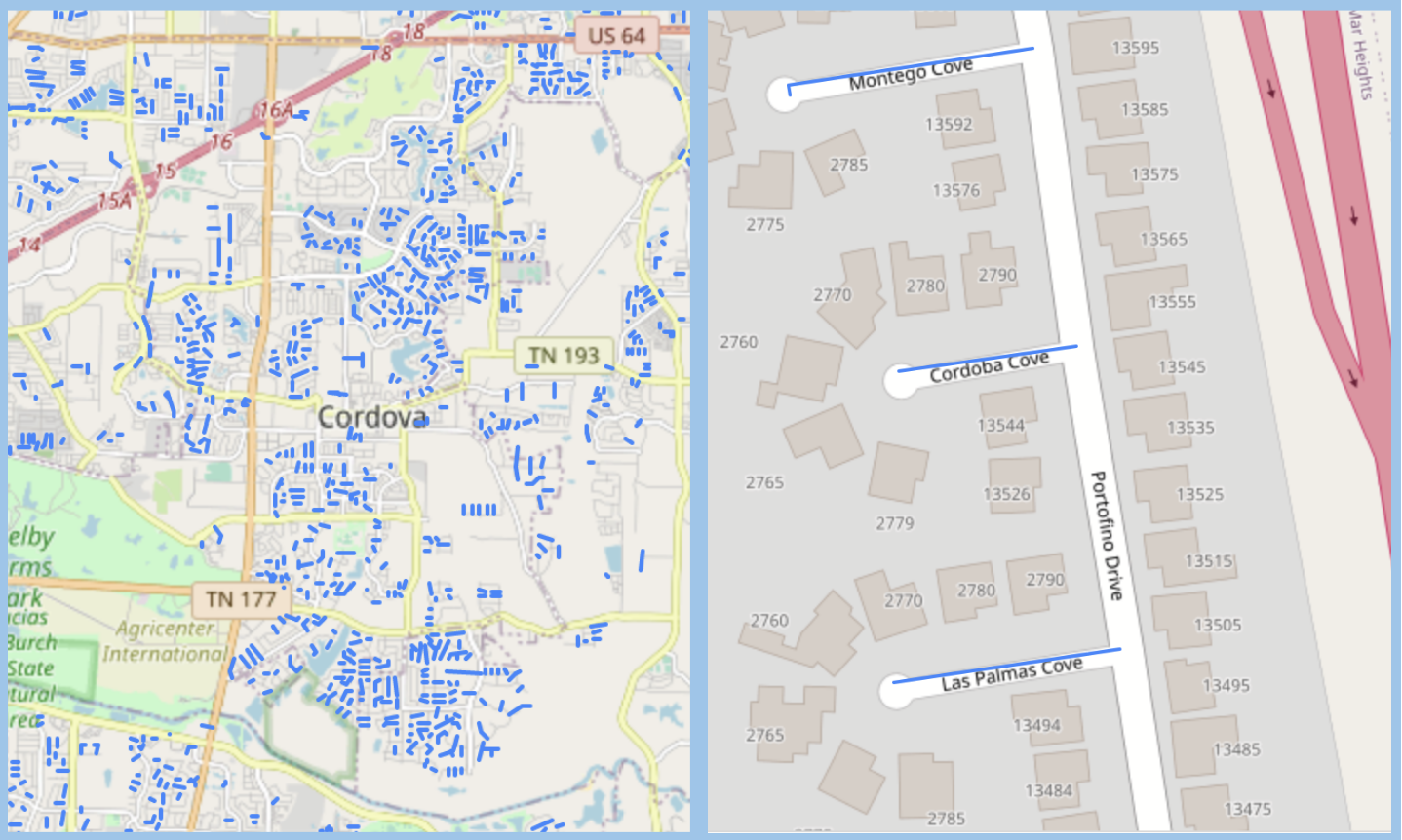 Left, The coves of Cordova, TN. Right, Cordoba Cove in San Diego, CA
Left, The coves of Cordova, TN. Right, Cordoba Cove in San Diego, CA
Why is it a Memphis Thing?
In their published Street Name Guidelines the public utility of Memphis and Shelby County, Memphis Light, Gas, and Water instructs developers to use the designator “Cove” for all cul-de-sacs. Unfortunately, I can’t find any references to why they chose this as the single designator for cul-de-sacs 🤷♂️
In his blog, Crème de Memph, Josh Whitehead details the history of the first cove in Memphis. The developers hadn’t yet got the memo, since technically it’s a “Way”. Interestingly to me, I think I have actually visited this cove on a walk during a recent visit to Memphis while staying in a nearby Air-BnB for my cousin’s wedding.
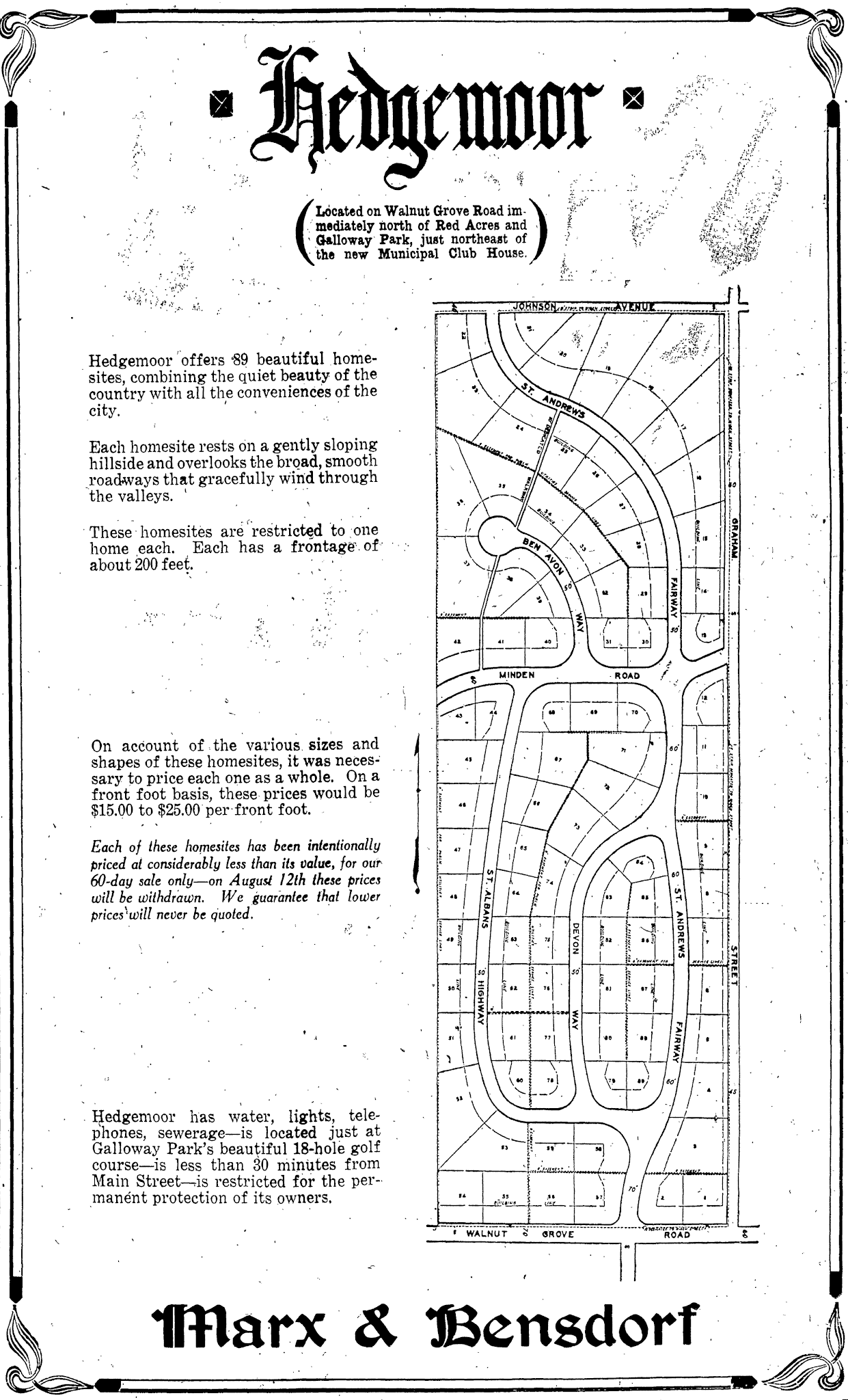 A subdivision plat in a an ad in the June 13, 1926 Commercial Appeal
A subdivision plat in a an ad in the June 13, 1926 Commercial Appeal
Data and Code
Part of my inspiration for this project was an opportunity to experiment with DuckDB and its spatial extension.
All of the code is available in this GitHub repository.
DuckDB is an in-process analytics database. It does a great job of quickly analyzing large amounts of data without having to worry about memory constraints or setting up a database server. It ripped through the 10GB 18+MM row roads dataset with no problems. It also has great integration with Python. Overall I’m really impressed with DuckDB and looking forward to using it more.
There were a couple of times I wish using it was a little more smooth. For example, the spatial extension can read remote shapefiles via the httpfs extension, but it cannot read zipped shapefiles. So I used geopandas to download, unzip and read the remote shapefiles and save them locally to parquet for DuckDB to ingest. Similarly, DuckDB wasn’t able to read a raw CSV file hosted on GitHub because it wasn’t encoded in UTF-8. I had to use pandas to read the CSV. I also couldn’t find a way to read spatial data from DuckDb into a geopandas GeoDataFrame without first writing it out to disk as a geojson or other spatial format and then reading it back in. Certainly, none of these are deal breakers, but I think some of these would make good features in the future.
Downloading and Ingesting data into DuckDB
In the code block below, I used requests and BeautifulSoup to get the paths to the zipped shapefiles containing the road data for each US County. The data is hosted on the US Census Bureau’s FTP site. Then using geopandas, I unzipped and read the shapefiles into GeoDataFrames and saved the data locally as parquet files. Finally, I created a spatial table in DuckDB containing the data from all the downloaded parquet files. I used a similar process to download and ingest county and state data.
import re
from pathlib import Path
from bs4 import BeautifulSoup
import duckdb
import geopandas as gpd
import pandas as pd
import requests
from tqdm import tqdm
Path("./data/roads").mkdir(parents=True, exist_ok=True)
Path("./data/counties").mkdir(parents=True, exist_ok=True)
Path("./data/states").mkdir(parents=True, exist_ok=True)
# create duckdb database
con = duckdb.connect('data/roads.db')
con.install_extension("httpfs")
con.load_extension("httpfs")
con.install_extension("spatial")
con.load_extension("spatial")
# get the links to the zipped TIGER shapefiles
pfix = 'https://www2.census.gov/geo/tiger/TIGER_RD18/LAYER/ROADS/'
r = requests.get(pfix)
soup = BeautifulSoup(r.content, 'html.parser')
links = soup.find_all("a") # Find all elements with the tag <a>
links = [pfix + link.get("href") for link in links[6]
if link.get('href').startswith('tl_rd22')]
# use geopandas to read the zipped shapefiles
# and then save them as parquet files
# it doesn't seem like duckdb can read zipped shapefiles
pattern = r'_(\d{5})_'
for link in tqdm(links):
# regex to extract the county fips code from the link
matches = re.findall(pattern, link)
(gpd.read_file(link)
.assign(county_fips=matches[0])
.to_parquet(f'data/roads/{matches[0]}.parquet')
)
# create a table in the database containing the data
# from all the all the extracted road parquet files
con.sql(
"""
CREATE TABLE IF NOT EXISTS roads AS
SELECT * EXCLUDE geometry, ST_GeomFromWKB(geometry)
AS geometry FROM 'data/roads/*.parquet'
"""
)
Transforming and Filtering the Data
With the data loaded to my DuckDB database, I used the DuckDB Python API to transform, filter and aggregate the data down to just the cove data I needed. I was impressed with DuckDB’s support for regex, which made working with the string data pretty easy. (ChatGPT is great at generating regex btw.)
# Pattern to remove the direction from the name if it occurs at the end
direction_pattern = r' (N|S|E|W|NE|SE|SW|NW)$'
# Pattern to get the suffix from the name. Basically the last word
suffix_pattern = r'\b(\w+)\b$'
cove_count_q = f"""
with
suffixes as (
select FULLNAME,
county_fips,
regexp_extract(
regexp_replace(FULLNAME, '{direction_pattern}', ''),
'{suffix_pattern}')
as suffix
from roads where rttyp = 'M'
),
counts as (
select
county_fips,
count(suffix) cnt
from suffixes
where suffix = 'Cv'
group by county_fips)
select
lu.long_name,
counts.cnt as cove_count,
ST_AsWKB(counties.geometry) as geometry
from counts
left outer join county_fips_lookup lu
on counts.county_fips = lu.fips
left outer join counties \
on counties.geoid = counts.county_fips
order by cnt desc
"""
con.sql(
f""""COPY ({cove_count_q})
TO 'data/county_cove_count.json'
WITH (FORMAT GDAL, DRIVER 'GeoJSON')"""
)
# extract all the coves to a GeoJSON file
con.sql(
"""COPY (SELECT * FROM roads WHERE fullname like '%Cv%')
TO 'data/coves.json'
WITH (FORMAT GDAL, DRIVER 'GeoJSON')"""
)
Further Analysis and Mapping
With the transformed and filtered data saved out to GeoJSON files, I used geopandas to read the data back in to do further analysis.
county_counts = gpd.read_file('data/county_cove_count.json')
print(county_counts.head())
# long_name cove_count
# 0 Shelby County TN 4525
# 1 Travis County TX 1945
# 2 Williamson County TX 1231
# 3 DeSoto County MS 1181
# 4 Salt Lake County UT 669
# 5 Pulaski County AR 538
# 6 Madison County TN 537
# 7 Rankin County MS 400
# 8 Allen County IN 329
# 9 Hinds County MS 307
mid_south = (county_counts
.dropna()
[county_counts.dropna()
['long_name']
.str
.contains('TN|MS|AR')]
.cx[-93:-87.5, 32.1:]
)
print(mid_south.cove_count.sum() / county_counts.cove_count.sum())
# 0.445
memphis_metro = (county_counts
.dropna()
[county_counts.dropna()
['long_name']
.isin(['Shelby County TN', 'DeSoto County MS'])]
)
print(memphis_metro.cove_count.sum() / county_counts.cove_count.sum())
# 0.219
Finally, I used folium to create the interactive map embedded in the blog post.
import folium
coves = gpd.read_file('data/coves.json')
map = folium.Map(location=[35.09, -89.91], zoom_start=10)
folium.GeoJson(coves).add_to(map)
map.save('index.html')
What else?
I think there’s a lot more to dig in and uncover with this dataset. For one, I’d like to try to uncover other regionally specific road designations. The “Pikes” of middle and east Tennessee come to mind. Stay tuned to see if I can come up with anything.
And if anyone knows why Memphis calls cul-de-sacs coves, let me know.
Comments